

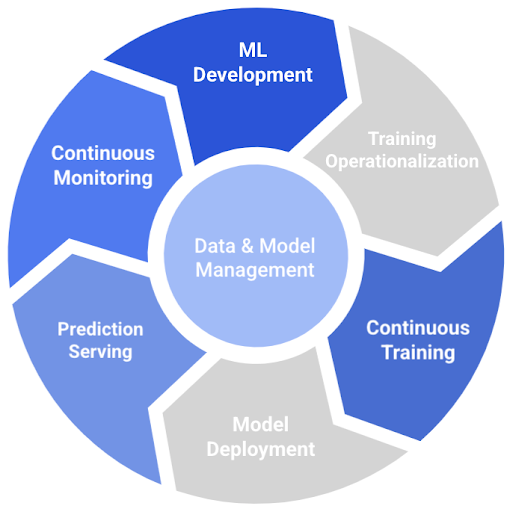
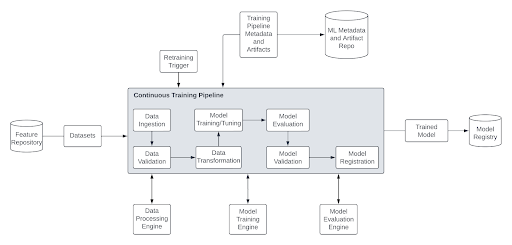
During the development and implementation of machine learning (ML) systems, a lot of time and effort is put by companies into training and deploying the model in production. Stacktics recognizes that most often there is a naive assumption that this system will continue working with an expected performance by training the model once. However, the changing nature of the data is constantly neglected. For example, as described in this article, 35% of the banks (included in the survey) reported a negative impact on the performance of ML models due to the COVID-19 pandemic. Unprecedented events like this clearly emphasize the need for continuous training in production.
There are many tools/libraries that can help design and deploy machine learning pipelines that incorporate MLOps best practices. These tools/libraries include TFX, Kubeflow Pipelines, Vertex AI Pipelines, SageMaker Pipelines, etc. We can integrate the retraining feature in these ML pipelines to make them CTML pipelines and achieve MLOps level 1 maturity (read more in this article).
There are multiple approaches to choosing when to retrain a given model, as described below.
Model retraining based on a specific interval is a naive way to implement CT. Too frequent episodes of retraining might incur high costs, and less frequent retraining might impact the performance of the ML system. Performance-based or trigger-based form data is more promising.
The CT journey doesn’t end here. The retrained model should also be deployed in production. There are many verification/validation steps involved in this. Some of them are as below.
Stacktics can help you implement and deploy CTML pipelines in production tailored to your specific use case. We have successfully implemented CTML pipelines for large enterprises across domains like e-commerce, banking, digital marketing, etc. We support implementation of ML pipelines end-to-end, including automated data preparation, hyperparameter tuning, model deployment, and CI/CD. Submit the Contact Us form and we can help you implement and productionize CTML pipelines so that you never need to worry about the degrading performance of ML models in production.
Have a question, get an answer. We would be happy to chat.