

With the progress of data science and the development of the digital marketing industry, big data becomes a fundamental consequence of the new marketing ecosystem. Fuelled by an increasing number of mobile devices, e-commerce channels and social networks at our disposal, 3.47 billion people globally had access to the internet by mid-2017. And, of course, Internet reach continues to grow steadily. (Internet penetration in China was 55.8 percent in 2017 and is expected to be 57.8 percent in 2019).
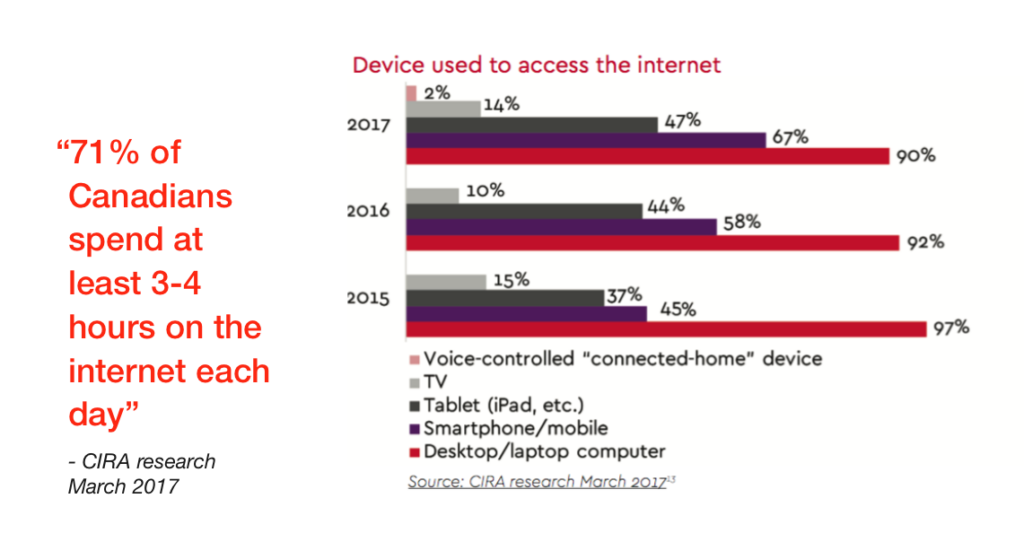
According to research from CIRA’s Canada’s Internet FactBook 2017, ‘Nearly three-quarters of Canadians spend at least three hours a day online. How are they spending this time? What are they doing and how are they accessing the internet? Learning more about Canadians’ behavior online can help organizations find ways to make the experience more useful and enjoyable for Canadians.’
In other words, terabytes of marketing data are created every day and the methods to explore and extract the most valuable data from the gargantuan lake of raw data to make valuable business decisions becomes the most important topic of discussion and almost the #1 challenge for data scientists in recent years.
To define big data, IBM data scientists break down big data into four V’s: Volume, Velocity, Variety, and Veracity.

To be more specific, one of the biggest challenges that marketing data scientists face today is how to manage big data effectively given the variety of analytics systems they are presented with – each has their own marketing organization’s data, processes and decisions. To break down this large challenge, the three most representative issues that marketing data scientists are facing include:
Selective Data Collection
Sometimes, quality is increasingly preferred over quantity when a data engineer is collecting data from anywhere online. A data scientist must always observe exactly what kind of data is being collected/considered and what specific purpose, reporting or predictive modeling is being used alongside any costs in both economic and time instances.
Selecting Analytical Tools
A successful and stable data pipeline can help make and enforce decisions in shorter timeframes as big data volumes grow. Companies like Google, Amazon, and Salesforce all provide a variety of solutions for building BigData pipelines, not only for offline data but also online real-time data. All of these products have unique features and selling points. For example – Google’s BigQuery is a fully managed, petabyte-scale, low-cost analytics data warehouse, whereas AWS’s Redshift provides similar features, but is based on the Amazon Redshift Cluster. Choosing the right tools and gaining enough experience in them is becoming a mandatory skill for marketing data scientists.
Selective Insight into Impact
Once data goes into the data lake, the way to clear it and eventually build it as a valuable statistic modeling is to return it into insights, then to use that insight to make a positive impact. This process is where data scientists spend the most of their time.
In conclusion, deciding how to play with marketing’s big data and its respective tools has become the hottest topic in recent years for data scientists. In order to acquire the biggest business benefit from massive raw data availability that is generating every day on the Internet, data scientists should keep their hands dirty not only on data manipulation through the plethora of cloud tools available, but also have the ability to set up mathematic modeling to represent the value of the mentioned huge amounts of data.
References:


