

Tactical Testing Is For Amateurs
Most optimization work in digital marketing is purely tactical. There will be some understanding of larger goals and opportunities, but the over-riding need for the people doing much of this work is to come up with a quick win (or soften a loss) for the meeting at the end of the week. Optimizations do still need to win tactically of course, but the impacts that will move the needle on executive summaries are much more likely to come from a deliberate, rationalized assessment of the big picture, rather than spamming out tests and hoping to win the tactical lottery. Tactical optimization is simply whacking away at the nearest mole. As a professional you are looking to maximize ROI, and that means a strategic approach to optimization – stepping back to consider logically where, when and how you are most likely to generate maximum value; where your work will build a legacy of value.
What Should I Optimize?
Your enterprise marketing systems will help you to construct your tests, but there is usually little guidance to help with the more strategic and significant decision underlying your impact on business results – what to optimize. Simply, optimization should be applied to everything that carries an expectation of producing a positive return on the time, resources and opportunity cost invested to produce that return. In practical terms however, this list often stretches into the impossible distance and can bog you down in low impact churn. The question you will most often be faced with is “what should I optimize next?”.
Optimization should be prioritized towards whatever holds the highest probability of producing the greatest increase to value generation, over the time frame relevant to your business. This probability should be evaluated based on relevant historical or industry benchmark data where possible, though intuitive judgements often remain both valuable and necessary. A balance must be struck between the lift & scale of the potential positive impacts, the lift & scale of the potential negative impacts, and the probability of each result.
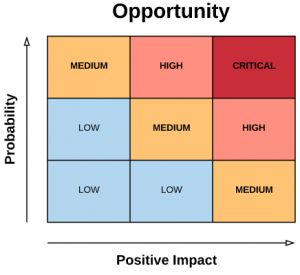
In the above table, Impact is defined as Scale * Lift. For example, in testing the landing page of a limited-time marketing offer, a positive result may convey its benefits to only the remainder of that offer period, and if a positive result is not immediately achieved there may not be enough time (a large enough scale of impact) remaining to justify a second round of testing. If the potential is seen for particularly large lifts however, a short, focused test on a high traffic landing page can yield very desirable business results over even a short time. In contrast, the design of long running conversion funnel pages may already be well optimized, offering low likelihood or strength of lift, but if those pages are expected to remain the path for all converting users for years to come, the large lifetime scale may still indicate a significant opportunity to grow value generation. In a perfect world, your optimizations will increase the profitability of an area of investment, allowing it to scale up to a higher volume – this incremental scale is directly attributable to your optimization work, and in turn makes the area a greater opportunity for follow-up optimizations. Positive feedback loops – for fun and profit!
Finally, it is important to recognize that testing is often needed to fulfill a second strategic business role – explicitly generating insights to inform planning, or generating data to arbitrate between the differing intuitions of stakeholders. While these test scenarios fall outside of marketing optimization in the traditional sense, they often remain highly valuable in positioning the business for future success. The widest possible perspective should be maintained in assessing where and how the greatest positive impact to the business can be achieved. There are many types of value, and it pays to think big.
Which Variables & Values Should I Include In My Test?
All optimizations should be tested. This can sometimes be difficult technically (e.g. changing the entire flow or design of your website), but without finding some way to evaluate the impact of your proposed change, you won’t be able prove how valuable your work is, or even be positive that you’re making correct decisions.
As with the broader optimization focus, test variables (e.g. imagery used) should be selected from those most likely to produce the largest net gain to value generation. To this, test design adds the complexity of controlling the number of variables and values to ensure a reliable result within the desired time frame.
For all tests, but particularly for those designed to resolve points of discussion, data must be with properly collected and interpreted to fulfill its role as an impartial arbiter. In these cases, particular care should be taken to establish explicit agreement on the variables & values to be included, the definition of success and any other test parameters to the discussion.
It’s worth developing an understanding of statistical relevance to inform your analysis and ensure that your test is set up to produce a reliable result, but that is too large a topic to wade into here.
What Test Structure Should I Use?
The two main approaches for organizing test values to produce statistically reliable results are A/B/n and multivariate.
- A/B/n is the most robust structure for testing between static groupings of variable values. This structure is particularly suited to working with strongly dependent variables or achieving a very high confidence result between a small number of variable values. When in doubt, A/B/n.
- Multivariate test structures operate at the level of the individual variable values, packaging them into specific combinations that will allow statistically reliable performance results to be gathered without the need to test every combination explicitly. Though multivariate tests usually require a larger data volume than A/B/n tests, they are an effective way to quickly cross-evaluate many values in a single test run, especially when there are more values being evaluated than can be feasibly included in a single A/B/n test.
When Should I End My Test?
Generally, a test should be ended as soon as it reaches a statistically relevant conclusion about your test hypothesis (you did define a hypothesis at the start of your test, right?). For carefully designed tests, this point should approximate the end date originally planned, though these will not always align exactly.
When testing within shorter durations of potential impact, a test should be paused before the originally planned end date if the remaining scale (duration of impact and expected positive lift) indicates a smaller likely positive impact than the resources that it will take to implement the test’s indicated changes.
Appendix – Technical Definitions
I’ve tried to maintain balance between readability and precision in my phrasing through this post, but for anyone interested here are some more precise definitions of the concepts discussed.
Potential Scale – the number of opportunities for value to be generated over the remaining lifetime of the test values (e.g. impressions in ad testing, page views in webpage optimization, etc.).
Scale = OpportunitiesPerTimeSegment * TimeSegments
Test Scale – The number of opportunities for value to be generated during the test period.
Scale = OpportunitiesPerTestTimeSegment * TestTimeSegments
Lift – the space (expressed as a positive or negative) between benchmark performance and the measured performance of given combinations of test values.
Lift % = (ElementPerformance – BenchmarkPerformance) / BenchmarkPerformance
Expected Lift – a prediction of lift which combines the strength of likely lift outcomes across both the positive and negative spaces into a single averaged value. Because the space of possible outcomes is infinite, this must be projected based on an estimation of the relative likelihood and strength of the aggregate positive and negative outcomes.
Potential Lift – the highest positive lift which can be solidly expected, inferred from as strong a grounding in benchmark data as is possible. This is relevant due to the discrepancy between the potential scales of statistically grounded positive and negative test results, where positive outcomes are maintained and negative ones immediately discarded.
Impact – the total value (expressed as a positive or negative) generated during a test run, and potentially also through the longer term implementation of test recommendations, relative to benchmark data.
Impact = Lift * Scale
Expected Impact – a prediction of lifetime impact which incorporates the underlying scale, expected lift and potential lift values.
Expected Impact = (ExpectedLift * TestScale) + (PotentialLift * PotentialScale)


